网页知识
# 网页知识
——通过这篇文章了解我们为您提供网页知识的使用方法及场景
# 网页知识的作用
我们希望您在了解网页知识功能之前,了解它的场景及用途:
● 使用场景:企业的许多知识保存在公开网页里,需要通过低成本方式将网页知识快速传入知识库,并且需要支持网页更新的同步能力。
● 用途:知识中心支持通过URL直接将网站中的知识同步至知识中心。此处需要您填写公开网址,我们将遵循robot.txt协议获取网页内容。
# 如何创建并设置网页知识
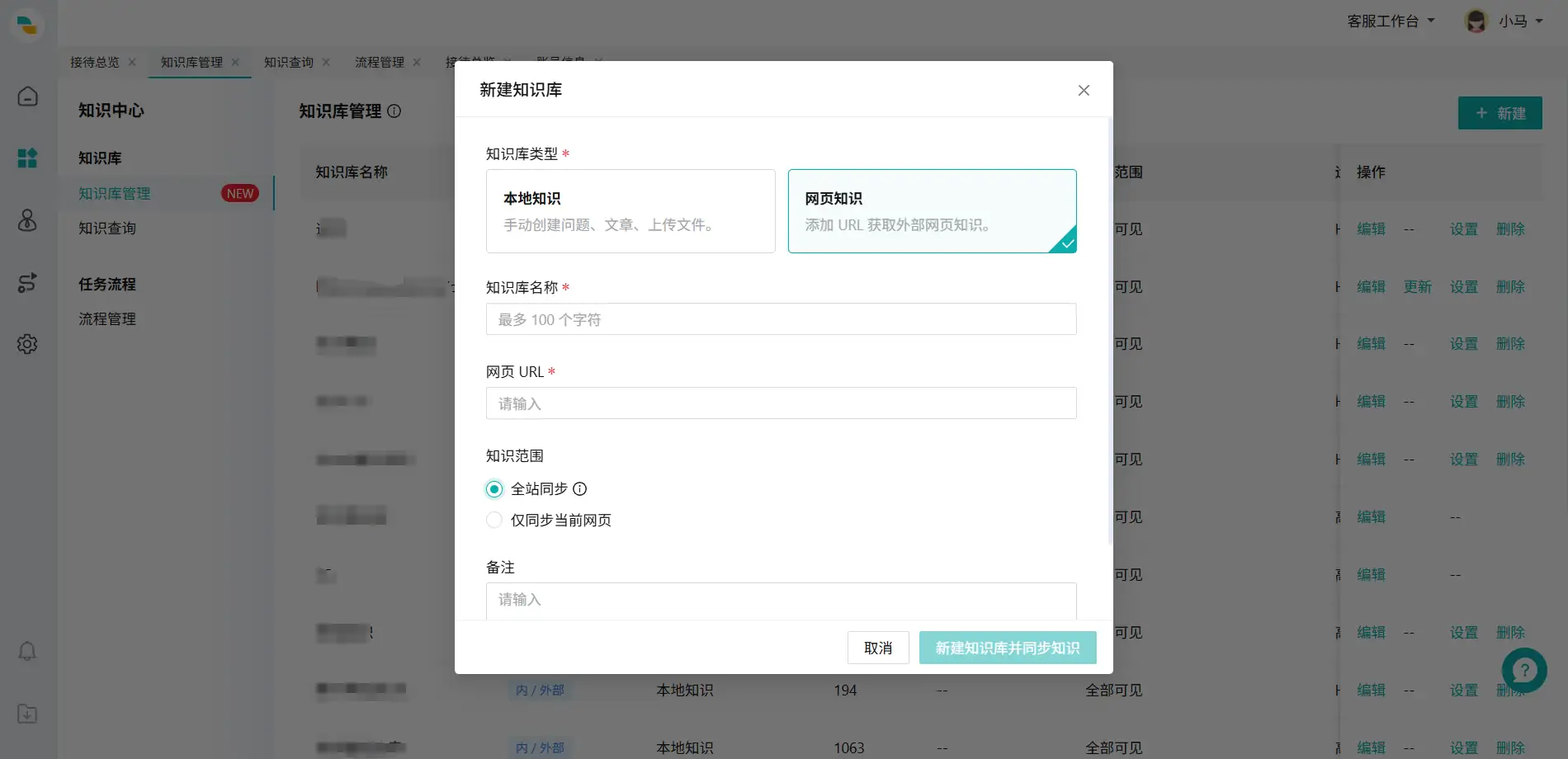
1.在【知识库管理】页面,点击【新建】按钮,建立网页知识知识库。
2.编辑知识库:筛选、设置知识库。
3.更新知识库:支持对整个网址进行同步更新;知识更新过程中将会失效,为避免影响大模型机器人使用,建议不要在客户咨询高峰期更新。
# 逐层获取 & 按照Sitemap获取
目前全站同步支持两种模式,您可以基于实际情况选择。
| 类型 | 按照Sitemap获取 | 逐层获取 |
|---|---|---|
| 说明 | 按照网页提供的sitemap爬取网页 | 从一级网页上获取所有url后向下钻爬虫,第二层继续获取所有url并向下钻爬虫,一层层向下爬虫 |
| 优点 | 可以限制网页获取范围 | 适用于绝大部分网页 |
| 缺点 | sitemap维护不全,获取网页数量不全 | 无法限制网页的获取范围,可能会同步一些对于企业客户不重要的网页 |
# 网页同步失败说明
如果您在同步网页失败,可以按照以下流程排查原因:
检查网站下是否存在robots.txt文件:
a. 当网站不存在robots.txt文件时,视为网站未授权第三方爬虫,会返回“网页禁止获取内容”。要查询网站下是否存在robots.txt文件,您可以通过在网站根目录后添加/robots.txt来查询网站的robots.txt文件,例如网页www.example.com/product/129330/ (opens new window)的robots.txt文件可通过www.example.com/robots.txt (opens new window)来查询。关于robots.txt的说明,可参考Google官方文档https://developers.google.com/search/docs/crawling-indexing/robots/robots_txt?hl=zh-cn (opens new window)。
b. 如果查询结果为空,需要为网站添加robots.txt文件,添加方式可参考https://developers.google.com/search/docs/crawling-indexing/robots/create-robots-txt?hl=zh-cn (opens new window)
检查网站robots.txt文件的User-Agent、Disallow和Allow:这三个字段定义了爬虫工具的网页爬虫范围。如果您输入的网页在Disallow的路径内,会返回“网页禁止获取内容”(Disallow: /代表所有网页不能爬虫)。如果您输入的网页在Disallow的路径内,请修改robots.txt协议的内容,例如变更为Allow: /
全站同步-按照 Sitemap 获取时,检查网站的sitemap文件:
a. 全站同步模式下,智齿目前会根据网站robots.txt的sitemap内子网页作为同步目标。关于sitemap可参考Google官方文档的介绍:https://developers.google.com/search/docs/crawling-indexing/sitemaps/overview?hl=zh-cn (opens new window)。如果robots.txt内不包含sitemap文件,会返回“网页禁止获取内容”。在此情况下,建议您为网站添加sitemap文件。
b. 在获取sitemap中的子网页时,我们会筛选出与您输入网址路径一致的网页并同步其内容(例如输入www.example.com/product (opens new window) 时,会筛选出www.example.com/product/129330 (opens new window)等网页,而不会同步www.example.com/helpcenter (opens new window)等无关网页)。如果sitemap中不包含与您输入网址路径一致的网页,会返回“网页禁止获取内容”。在此情况下,建议您在全站同步网页时尽量输入顶端域名,或者补充完善网站的sitemap。
单个网页同步失败
a. 检查网页是否能正常打开:查看浏览器是否能正常打开网页,如果网页异常,则无法爬虫。
b. 尝试“重新同步”:部分网页爬虫时可能连接超时,尝试重新同步,可能同步成功。