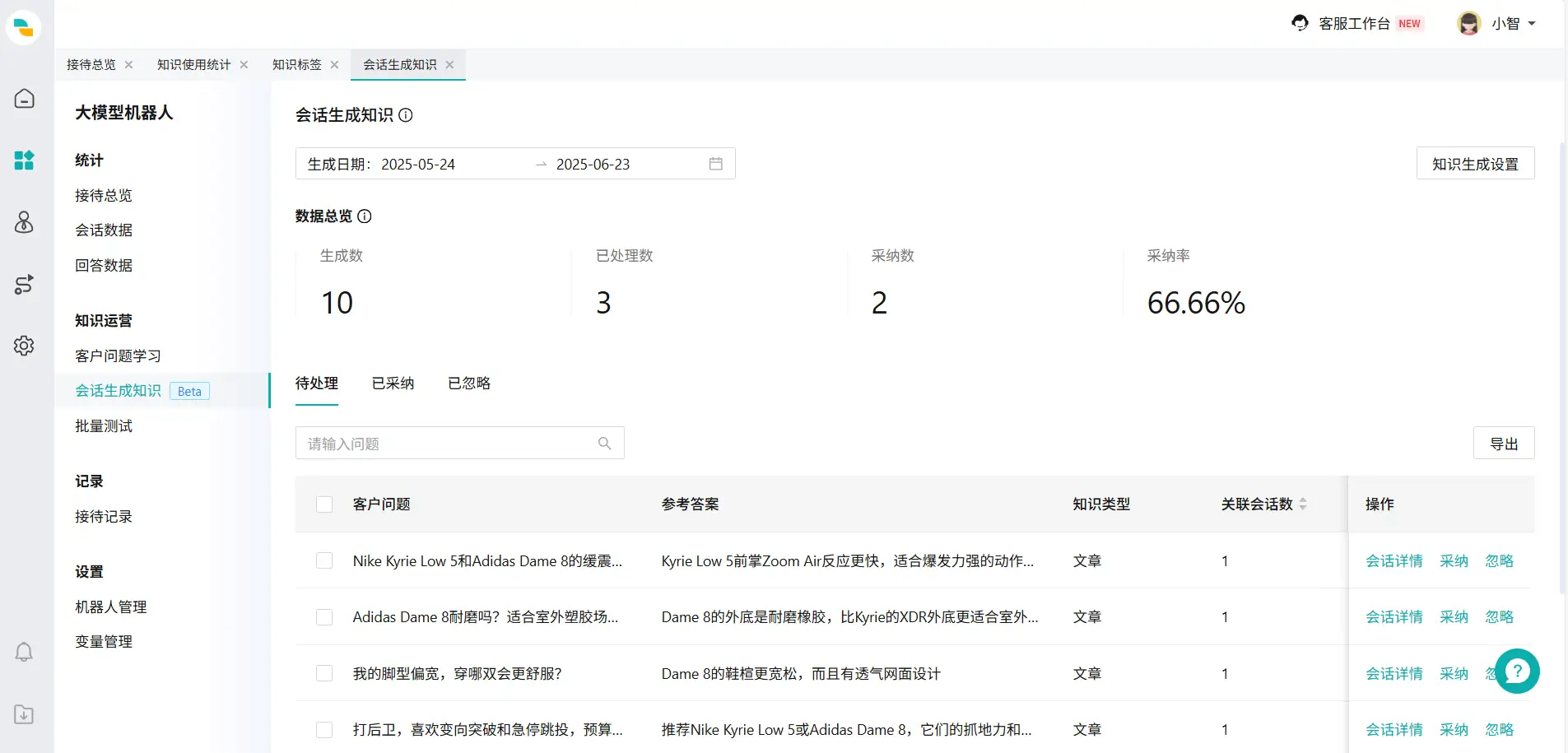
会话生成知识
# 会话生成知识使用指南
——通过这篇文章帮助您了解如何使用会话生成知识功能
# 功能介绍
我们希望您在了解【会话生成知识】功能之前,了解它的场景及用途:
● 使用场景:
- 冷启动阶段。如果您的机器人知识库维护不足,可以通过该功能学习历史人工客服会话,快速完成冷启动,提高知识库的知识覆盖率。
- 持续运营阶段。如果您的机器人独立接待率较低,可以通过该功能学习机器人转人工后的客服会话,让机器人学习人工客服是如何解决同类问题的,以提高独立接待率。
● 亮点:
- 根据历史会话快速生成知识,让您在几分钟内开始使用大模型机器人。
- 根据最近会话不断生成缺失的知识,自动过滤相似度高的知识。
- 自定义特定的客服、业务类型等条件,控制生成知识的会话范围。
# 如何使用会话生成知识
以下将给您介绍每个功能点的作用和效果:
# 配置从哪些会话中生成知识
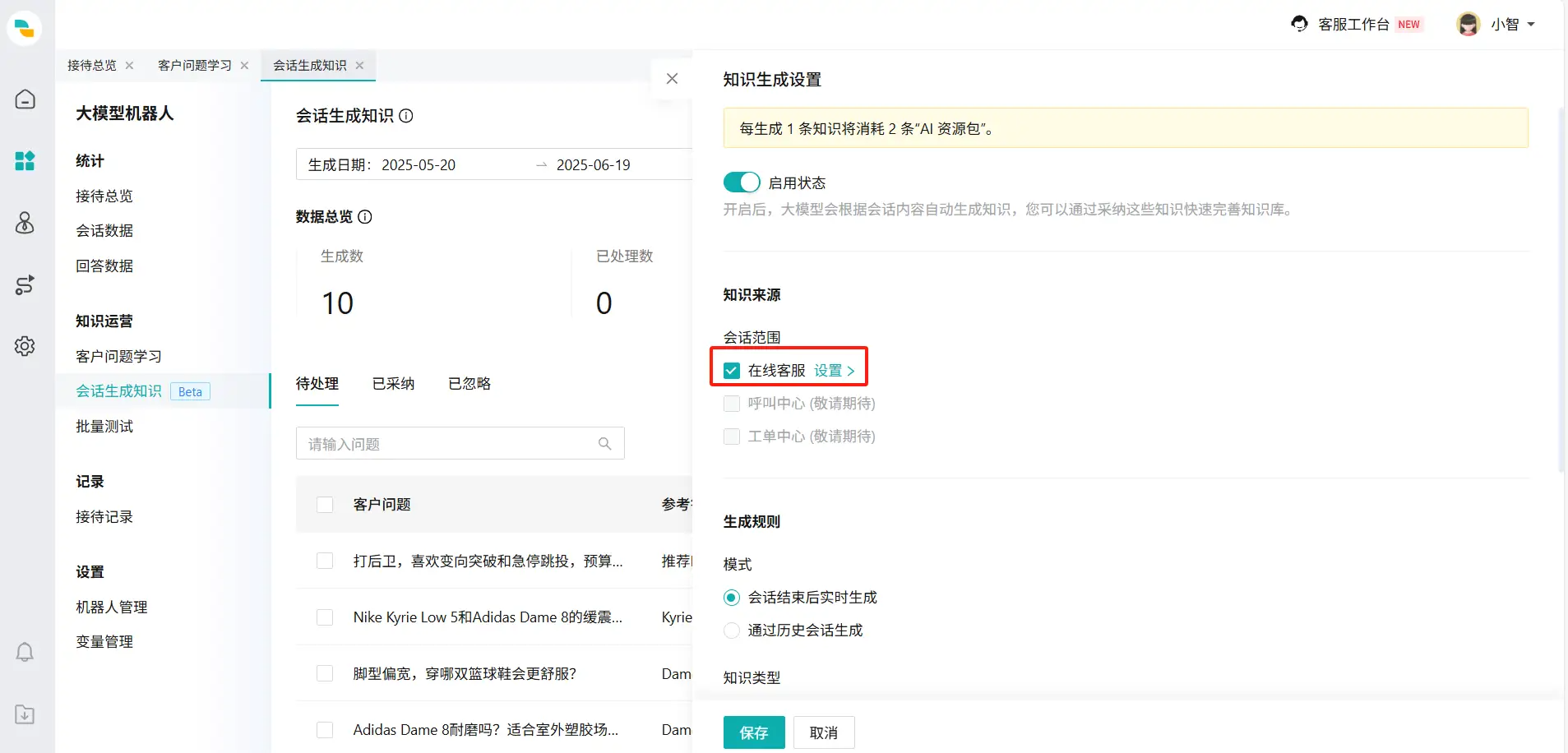
在【大模型机器人-知识运营-会话生成知识】点击【知识生成设置】,进行相关设置:
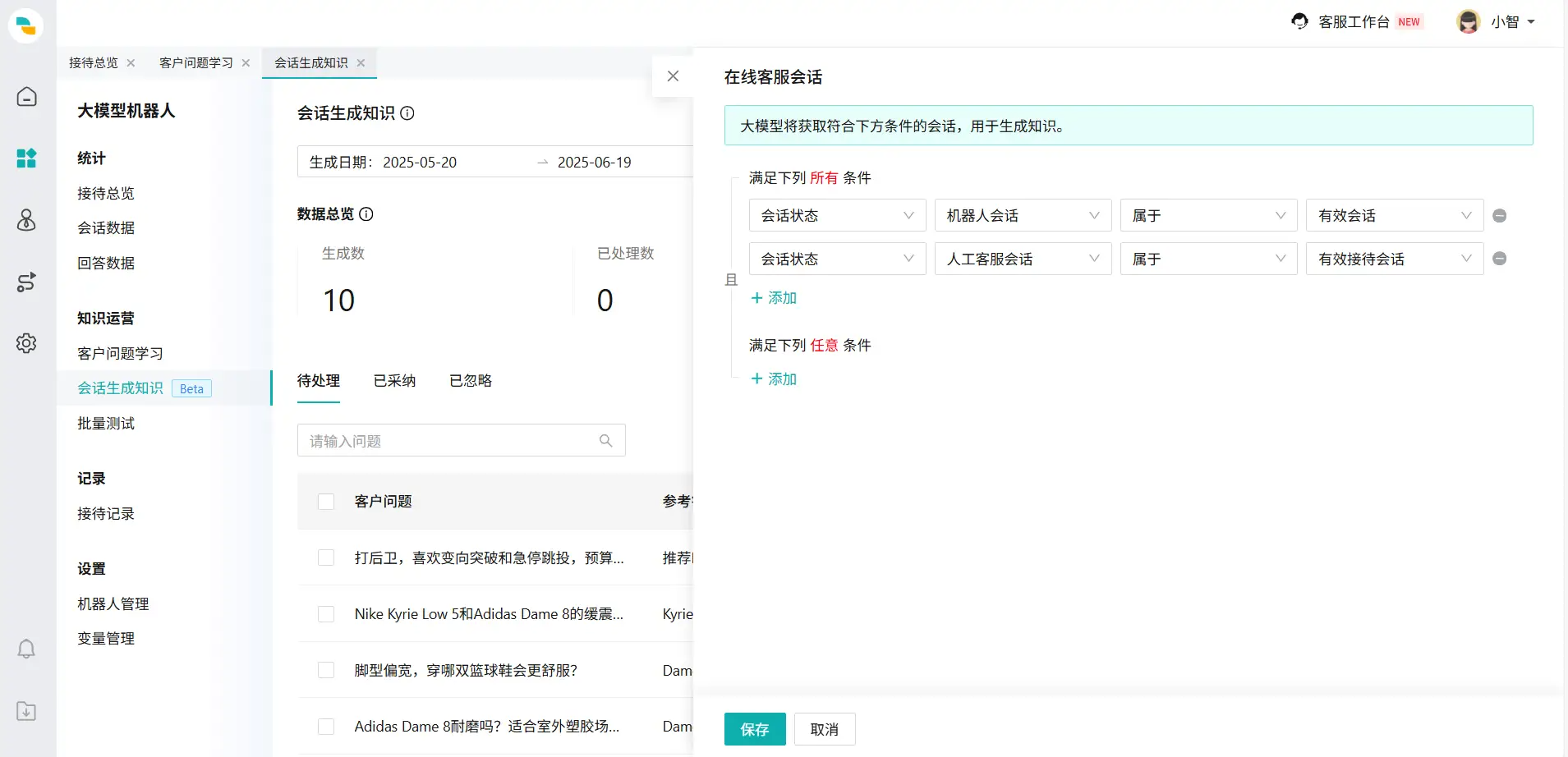
- 筛选会话范围: 在【会话范围】中点击【在线客服设置】,可以筛选会话范围。我们建议选择机器人和人工均为有效会话的会话,否则可能产生一些低质量会话。目前仅能学习在线客服会话,工单和呼叫通话尽情期待。
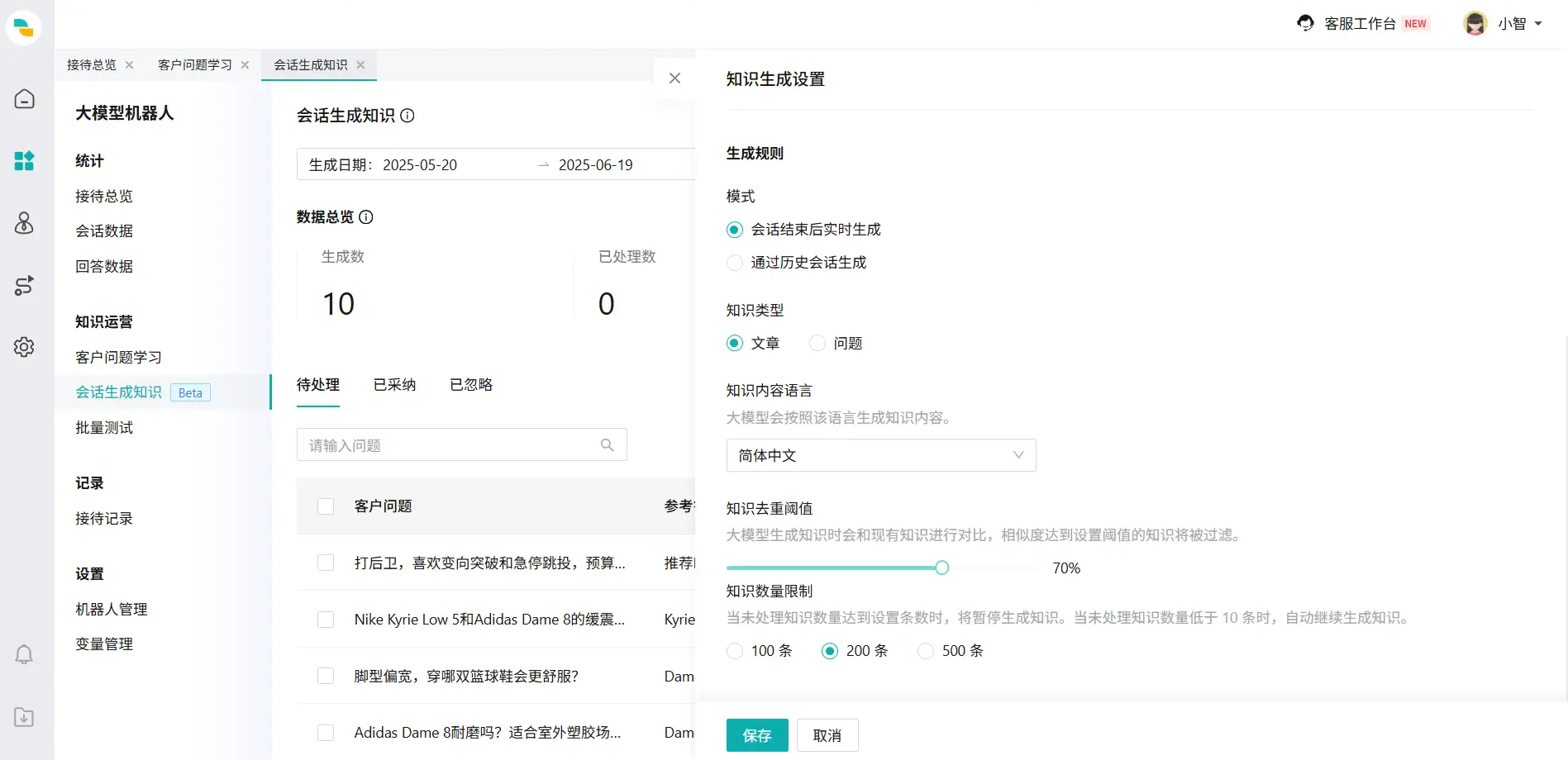
- 在生成规则中,我们可以指定会话生成的模式——会话结束后实时生成或者依据特定时间段的历史回话预计会话数量并生成知识(最大180天)。
- 可以指定生成知识的类型为文章或问题并进行多语言设置。国内支持简体中文、繁体中文、英语;新加坡和北美环境支持所有语种。
- 设置知识去重阈值:当遇到重复知识时,大模型生成知识时会和现有知识进行对比,相似度达到设置阈值的知识将被过滤, 阈值越高,生成知识的差异越小,阈值越低,生成知识的差异越大。
- 知识数量限制:当未处理知识数量达到设置条数时,将暂停生成知识。当未处理知识数量低于 10 条时,自动继续生成知识。
# 查看并处理生成的知识
在【会话生成知识】模块,您的知识会被分为3类:待处理、已采纳与已忽略。
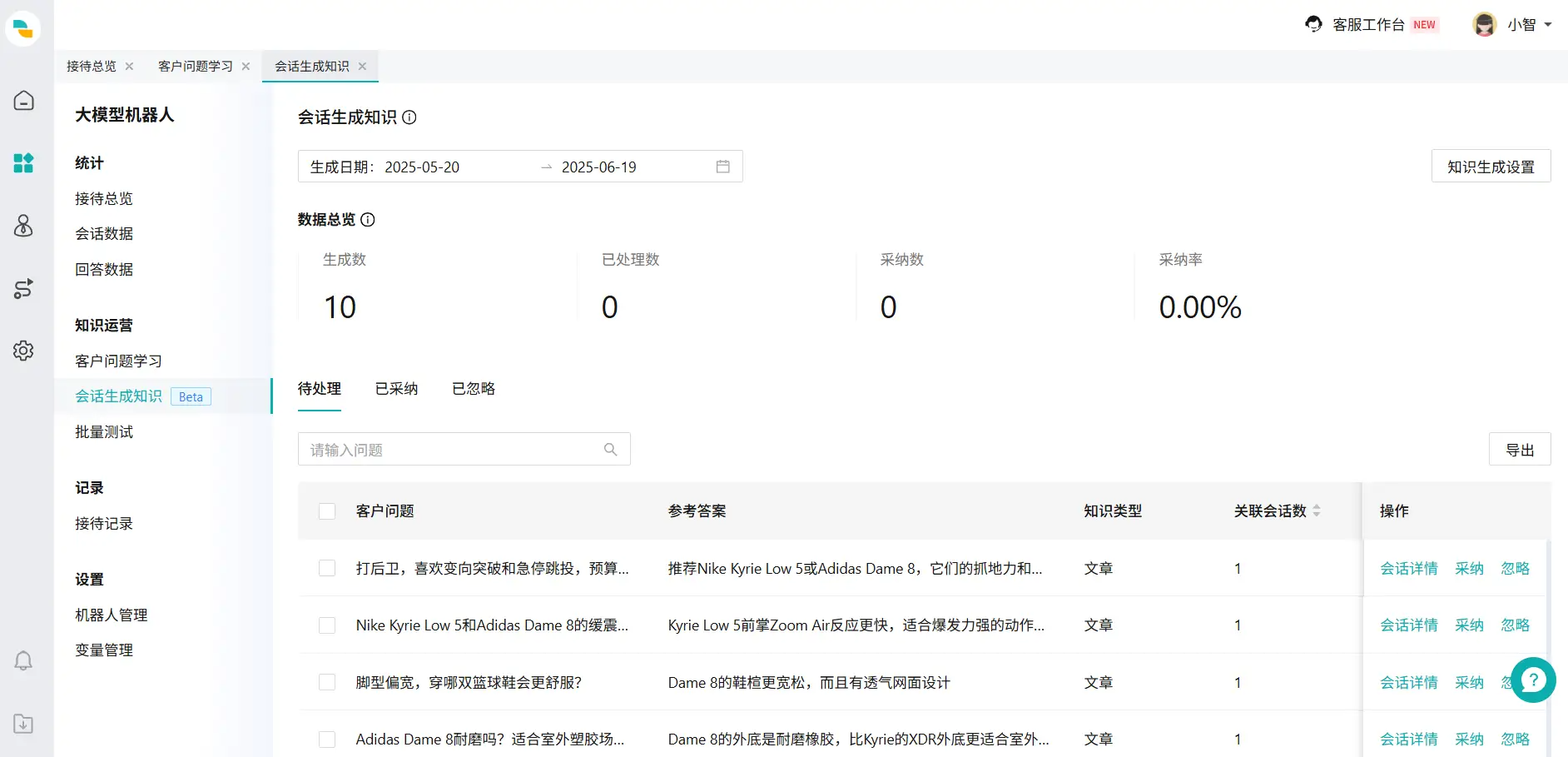
具体的指标如下:
| 指标 | 说明 |
|---|---|
| 生成数 | 大模型通过分析会话生成知识的总数量 |
| 已处理数 | 运营人员对已生成知识采取“采纳”或“忽略”操作的知识数量 |
| 采纳数 | 运营人员对已生成知识采取“采纳”操作的知识数量 |
| 采纳率 | 采纳率=采纳数/已处理数 |
点击【会话详情】,打开会话详情页(图6页面),查看该"客户问题"相关的所有回话。
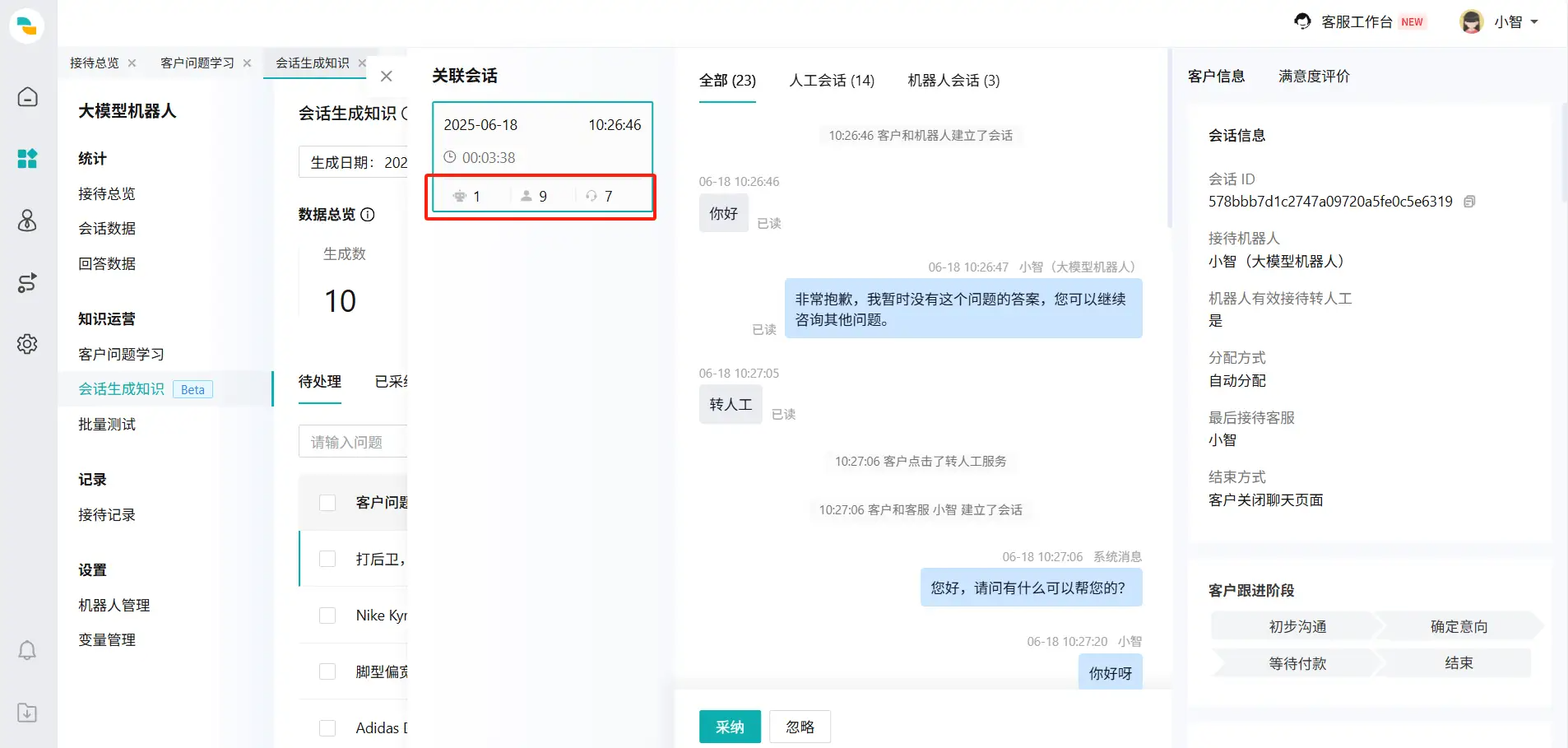
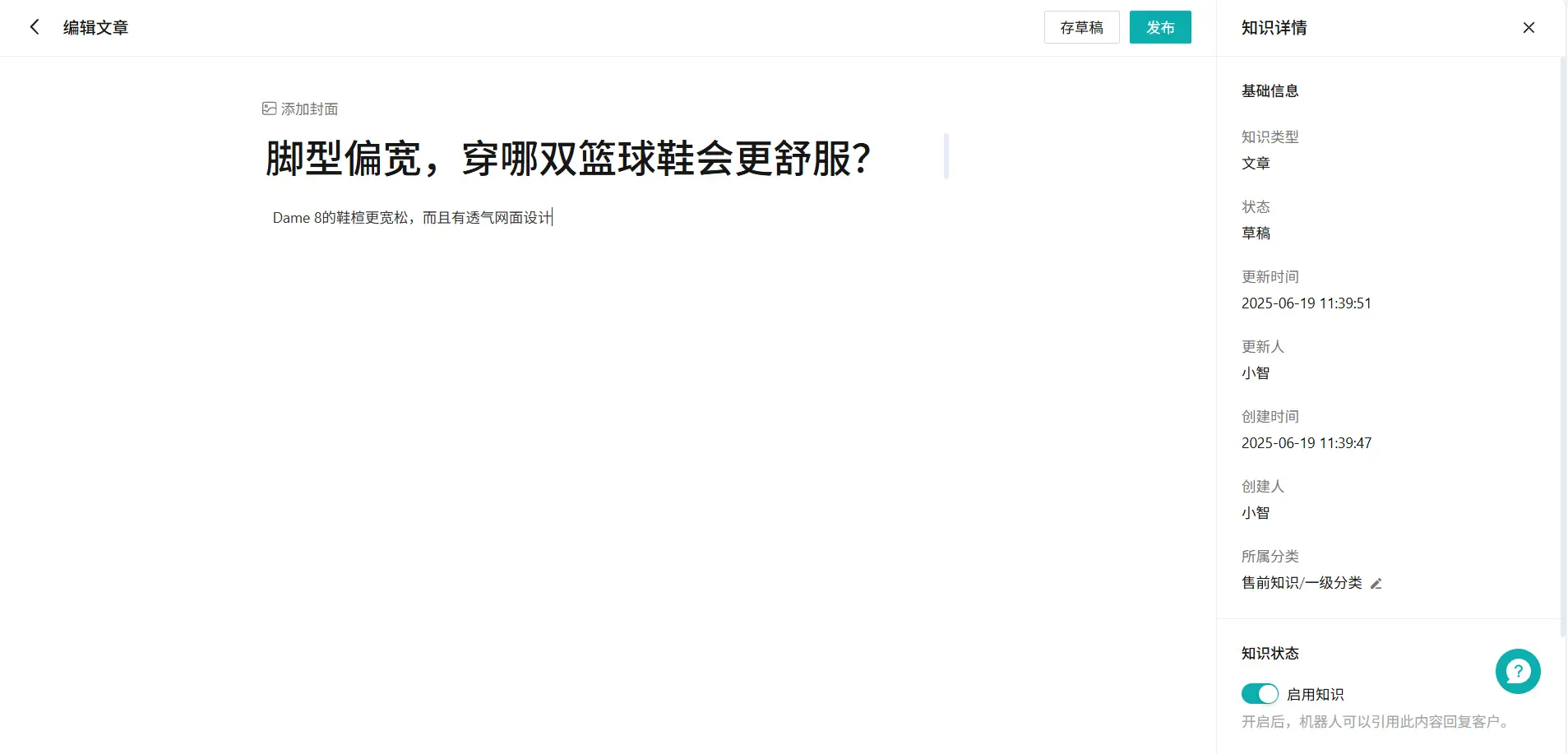
图6:会话生成知识完成后页面 点击【采纳】,首先,选择添加到哪个知识库、分类(图7页面);然后,进入知识详情页(图8页面)进行知识编辑。知识发布后,在已采纳页面(图9页面)就会展示已发布的问题与答案。
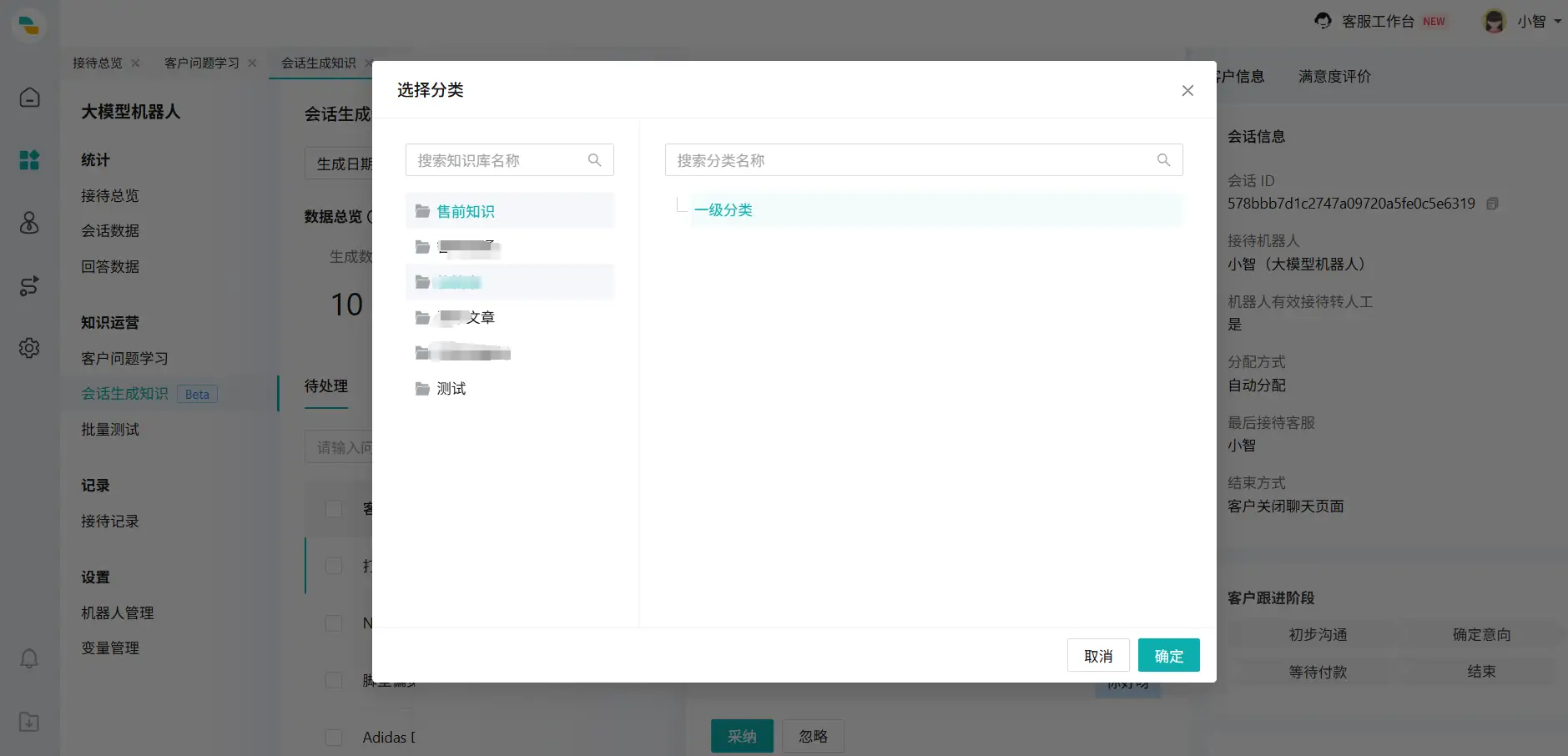
图7:点击“采纳"后页面
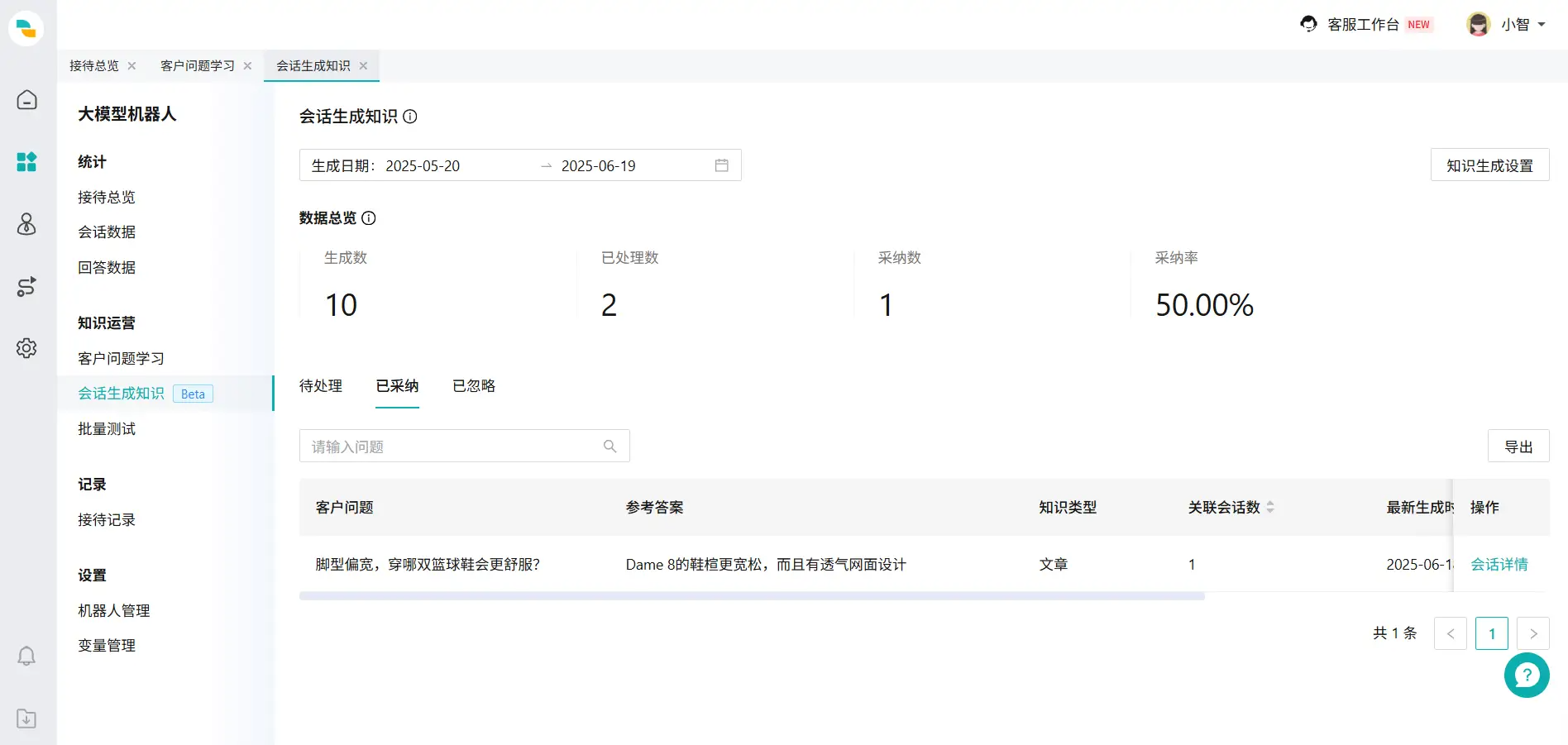
- 点击【忽略】,会忽略生成的问题与答案(图10),其中【会话详情】功能与待处理页面一样。
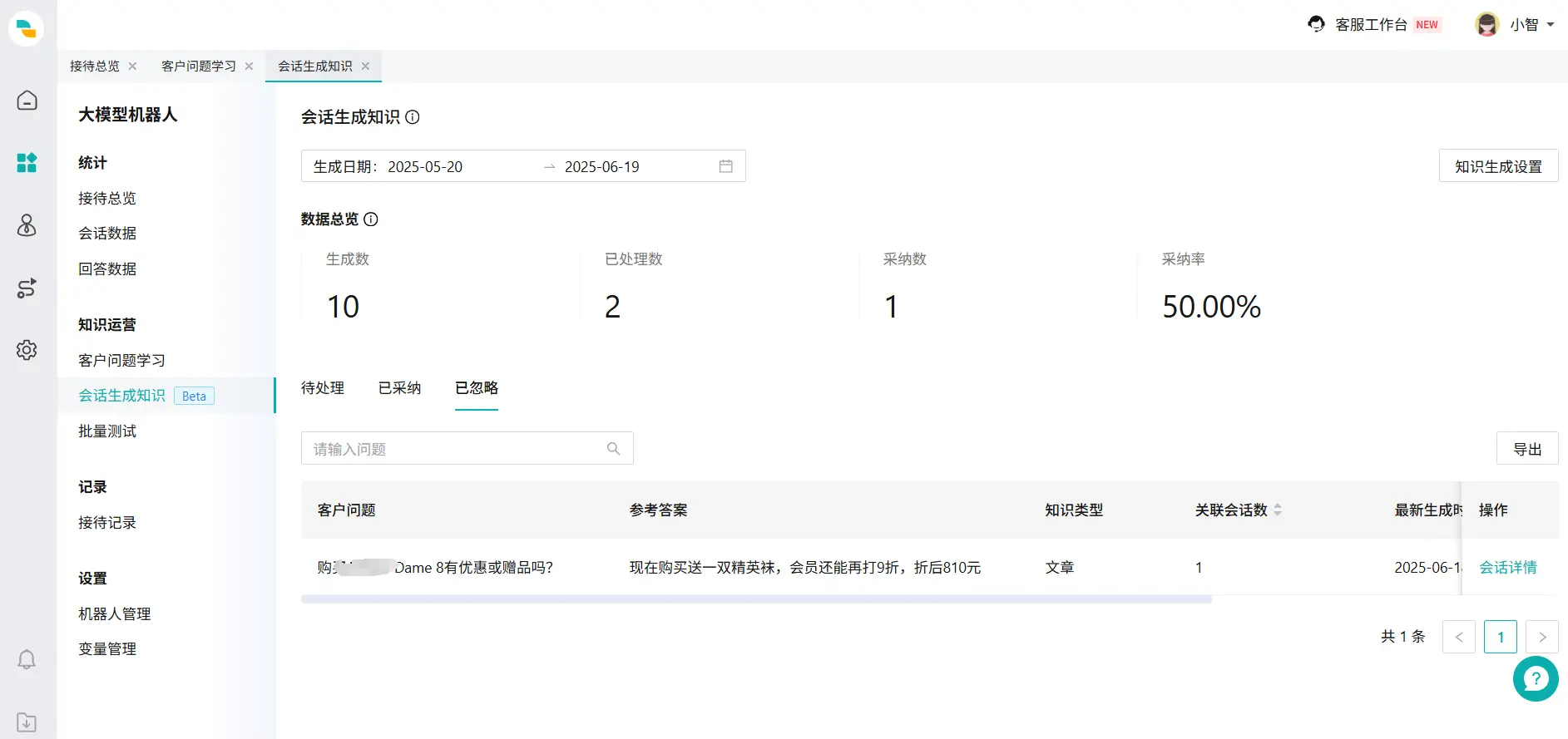
图10:已忽略知识页面
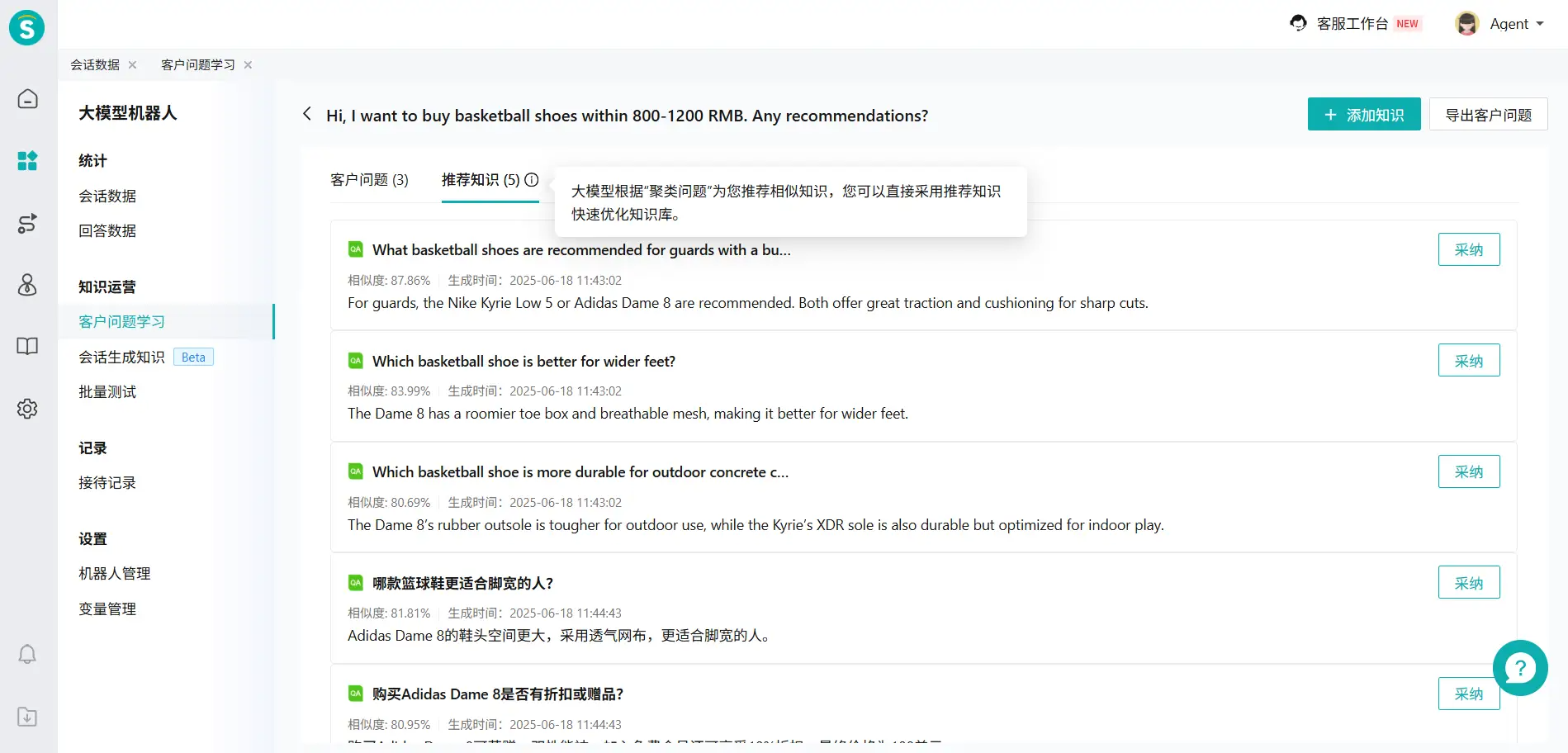
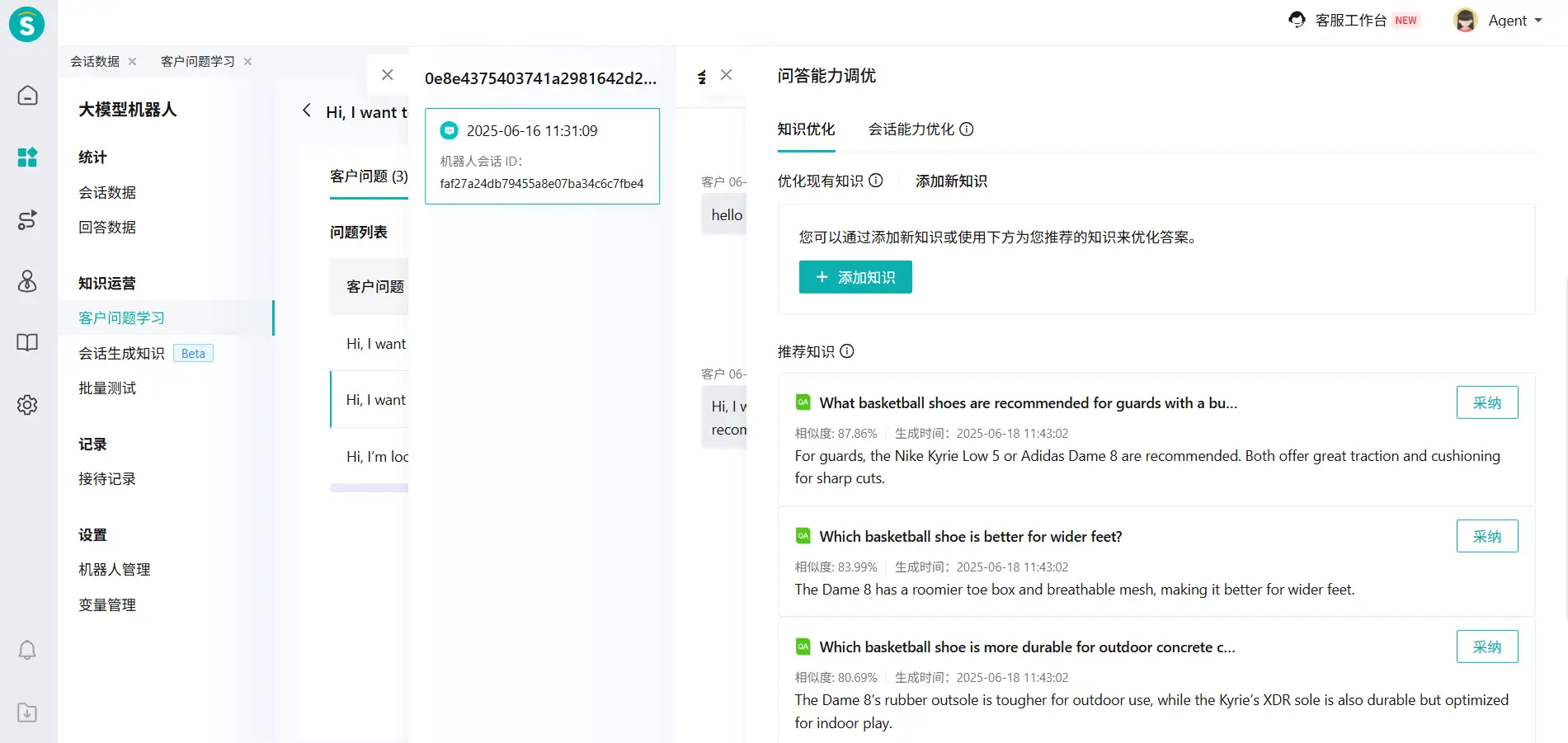
# 推荐已生成的知识
对于【客户问题学习-问题列表-聚类问题】中未处理的客户问题,大模型会依据聚类问题为您推荐【会话生成知识-待处理】内的相似知识。此外,在【客户问题学习-问答能力调优】可以添加推荐的知识,采用推荐知识快速优化知识库。
# 计费
国内每生成一条知识消耗2条AI资源包,新加坡和北美环境每生成一条知识消耗5条AI资源包。需要注意的是,如果一个会话如果内容较多,可能生成多个知识。
# 生成知识时的特殊处理
为了生成更符合业务需求、更有效、更安全合规的知识,智齿特进行了以下处理:
# 过滤会话
为提升处理效率并有效控制成本,在使用大模型从会话中抽取知识之前,我们会运用小参数模型开展初步筛选工作,以快速剔除不符合要求的会话内容。具体筛选标准如下:
- 需要人工介入或线下操作的对话: 此类对话涉及人工操作环节或需线下处理,例如“帮我重置密码”这类请求,由于无法通过知识问答完成,故予以过滤。
- 涉及个人隐私信息:包含个人身份信息(如身份证号、手机号等)、账户敏感数据(如余额、交易记录等)以及地理位置等可能泄露个人隐私的内容,均属于被过滤范畴,以保障用户隐私安全。
- 提问模糊:对于提问表述不清、缺乏关键信息的对话,如“它的功能是什么?”(未明确提及商品名称、产品型号等关键要素),因难以准确理解用户意图,予以排除
- 时效性短的答案:若会话内容涉及的知识或信息具有短期时效性,例如“这批商品的保质期是6月15日”,随着时间推移,此类信息将失去实际价值,故在筛选过程中予以过滤。
- 无有效信息的会话:包括仅包含问候语、结束语的对话,以及话题中断导致对话不完整的情况,由于此类会话无法提供有价值的信息,因此被过滤掉。
- 对话轮次过短或者对话轮次过长的会话:对话轮次过短,通常意味着信息量不足,难以满足需求;而对话轮次过长,则可能存在多个话题混杂、信息冗余等问题。因此,对话轮次过短或过长的会话均会被过滤。
# 知识去重
在实际业务接待中可能会产生较多同类型的会话。为了保证生成的知识不重复,我们会对知识会做以下去重和合并,以减轻您的知识运营压力。
- 我们会根据您设置的知识去重的阈值,过滤掉与知识库现有知识重复率高的知识。这样避免您重复采纳已经存在的知识。
- 针对已生成的相似知识,我们会进行合并处理,并同步统计与之关联的会话数量。例如您的业务中有多个会话都属于“因为网络导致账号登录异常”的问题,最终我们只会生成一个知识,并关联统计所有的相关会话。
上次更新: 2025/6/23 下午3:38:55
← 客户问题学习使用指南 接待记录→